Servidores Virtuales
Aplicación para minar las estadísticas de servidores virtuales Linux y Unix monitoreados obtenidas con la herramienta llamada vROps de VMWare. Ofrece estadísticas de servidores, virtuales y host en promedios por horas.
Este sistema es privado y está siendo usado por la empresa que lo financió. Por tal motivo, se hace cambio de toda la información que de alguna forma pudiera poner en riesgo la seguridad del sistema o la confidencialidad que espera el cliente. En el siguiente en lace se puede ver una copia pública modificada.
Repositorio GitHub: ServidoresVirtuales =>
Características de la aplicación
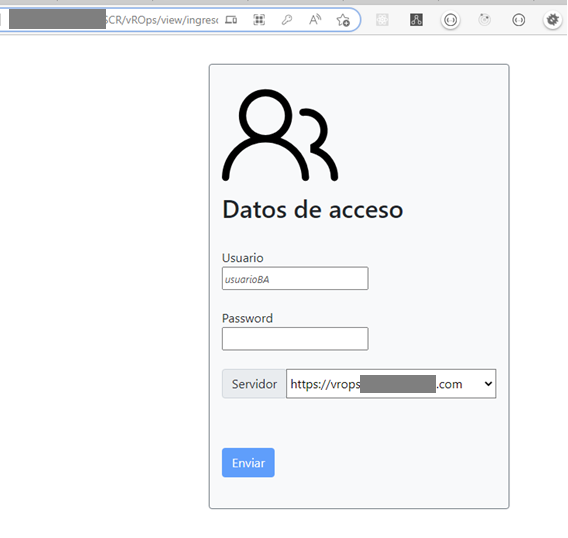
Objetivo
La aplicación tiene por objetivo, minar la data de las estadísticas de desempeño de los servidores virtuales de una plataforma de 450 servidores físicos y 1534 servidores virtuales, monitoreados por la la aplicación vROps de VMWare.
Detalles técnicos
La data a recolectar de las estadísticas incluía métricas de cpu, memoria y disco de los Host, los servidores en los que se hacen las virtualizaciones, y los virtuales.
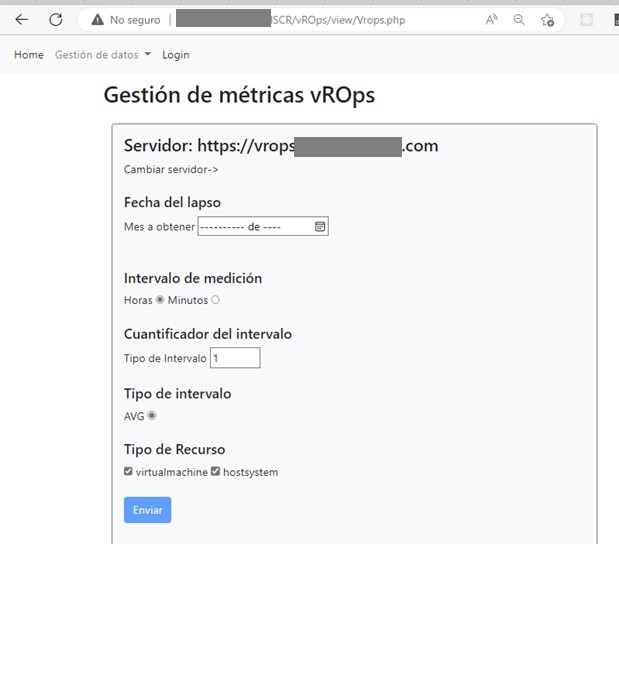
Métricas a ser captadas
virtualmachine (máquinas virtuales):[«cpu|usage_average»,»cpu|readyPct»,»cpu|costopPct»,»mem|vmMemoryDemand»,»mem|balloonPct»,»mem|consumedPct»,»virtualDisk|usage»,»guest|cpu_queue»,»guest|page.inRate_latest»,»guest|page.outRate_latest»,»guest|mem.physUsable_latest»,»guestfilesystem|percentage»,»guestfilesystem|capacity»,»guestfilesystem|usage_total»,»guestfilesystem|capacity_total»,»virtualDisk|totalReadLatency_average»,»virtualDisk|write_average»,»virtualDisk|totalWriteLatency_average»,»virtualDisk|read_average»,»virtualDisk|configured»]
hostsystem (Servidores padre):[«cpu|usage_average»,»mem|host_usagePct»,»mem|swapinRate_average»,»mem|swapoutRate_average»,»mem|host_provisioned»,»mem|vmMemoryDemand»,»mem|guest_provisioned»,»diskspace|total_provisioned»,»diskspace|total_usage»]
Retos del proyecto
Acceso a la información
La información a las estadísticas de desempeño, se realiza vía APIRest. Para ello creé una interfaz para parametrizar:
- El servidor desde donde se colecta la información.
- Los indicadores a ser colectados
- El lapso de tiempo y la frecuencia de medición. La muestras se toman por hora en este caso.
Esto permite flexibilizar la configuración de la extracción para hacerla de acuerdo a lo que se requiere en cada caso.
Volumen de datos
Tomar muestras por hora, por día de cada servidor, de un conjunto de más de 1500 servidores, genera un volumen de datos de entre 7 Gb y 11 GB.
Para procesar este volumen de datos, que incluso podía incrementarse, empleé archivos planos que garantizaran el procesamiento sin agotar la capacidad de memoria del servidor, en un tiempo razonable, transformando adecuadamente los datos de Json a estructurados
El tamaño de los bloques de información manejado en los archivos planos, se manejaba como parámetro, para que de esta manera hubiera la posibilidad de hacer ajustes de entonación.
Ver clase en GitHub: VropsResourceList.php
Almacenamiento

Los datos almacenados procesados y almacenados en archivos planos, se procesan por lotes y se pasan a una base de datos PostgreSQL que sirve de DataStage para que otros sistemas accedan y analicen los datos ya en formato estructurado.
Ver clase en GitHub: classCargarResourceList.php
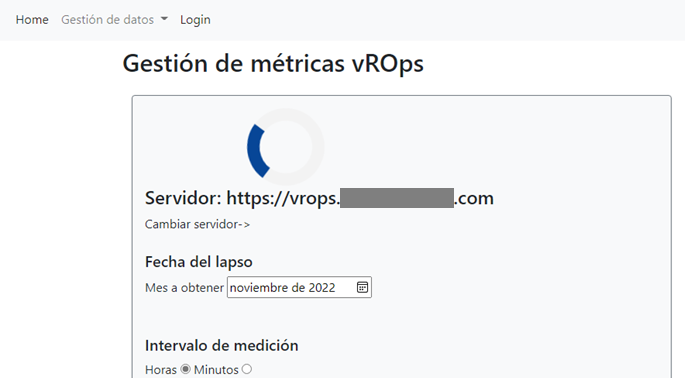
Cambio inesperado
Cuando el desarrollo estuvo prácticamente concluido, surgió un cambio inesperado que había sido antes una premisa fundamental, las métricas que estarían centralizadas, ahora podían estar en varios servidores, por un tema de balanceo de cargas. Esto obligó a hacer cambios en el flujo del programa, para que se tomaran las estadísticas por separado, se procesaran por cada servidor y luego se consolidaran.
También se hizo necesario identificar la duplicación de mediciones, que en teoría no sucederían, pero que en la práctica si sucedieron. Esto permitió identificar fallas en el sistema de medición (de sincronización de mediciones) que garantizaron que los resgistros eran únicos.
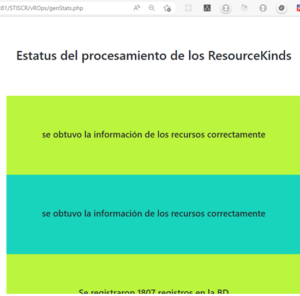
Reporte del procesamiento
Para mantener informado al consultor que realizaba el procesamiento, se añadió un sistema de reporte que notificaba los pasos que se iban alcanzando.
En ocasiones, por temas de limitaciones de red, de desempeño de los servidores, de demanda, u otros, el proceso no culminaba y quedaba en evidencia por los mensajes que se obtenían en el transcurso del procesamiento, volviéndose a procesar la información y asegurando además, la no duplicación de los registros.
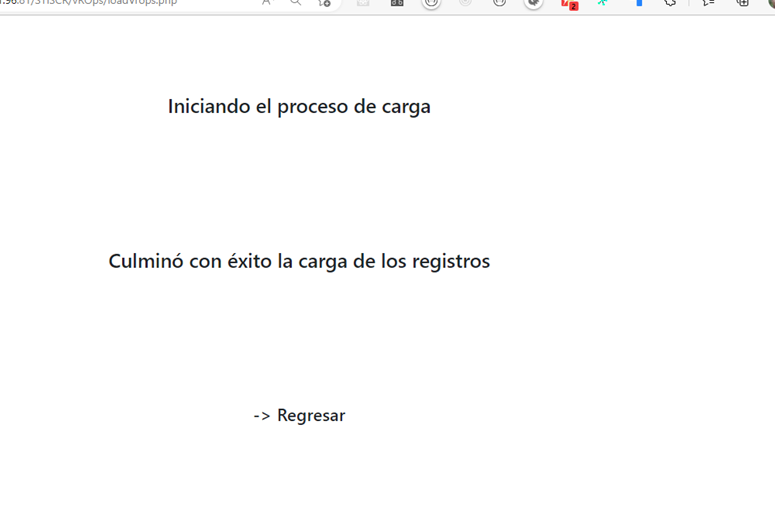
Fin del procesamiento
Al finalizar el procesamiento de todos los registros y el almacenamiento de la data en base de datos, se da un mensaje de culminación que permite saber al consultor que todo culminó como se esperaba.
Culminado el procesamiento, se eliminan los archivos planos y se limpian las bitácoras de información de avance del procesamiento.